達摩院開源具身智能“三大件” 機器人上下文協議首次開源
【環球網科技報道 記者 李文瑤】8月11日消息,在世界機器人大會上,阿里達摩院宣佈開源自研的 VLA 模型RynnVLA-001-7B、世界理解模型RynnEC、以及機器人上下文協議RynnRCP ,推動數據、模型和機器人的兼容適配,打通具身智能開發全流程。
具身智能領域飛速發展,但仍面臨開發流程碎片化,數據、模型與機器人本體適配難等重大挑戰。達摩院將MCP(Model Context Protocol)理念引入具身智能,首次提出並開源了RCP(Robotics Context Protocol)協議以推動不同的數據、模型與本體之間的對接適配。達摩院打造了名為RynnRCP的一套完整的機器人服務協議和框架,能夠打通從傳感器數據採集、模型推理到機器人動作執行的完整工作流,幫助用户根據自身場景輕鬆適配。RynnRCP現已經支持Pi0、GR00T N1.5等多款熱門模型以及SO-100、SO-101等多種機械臂,正持續拓展。
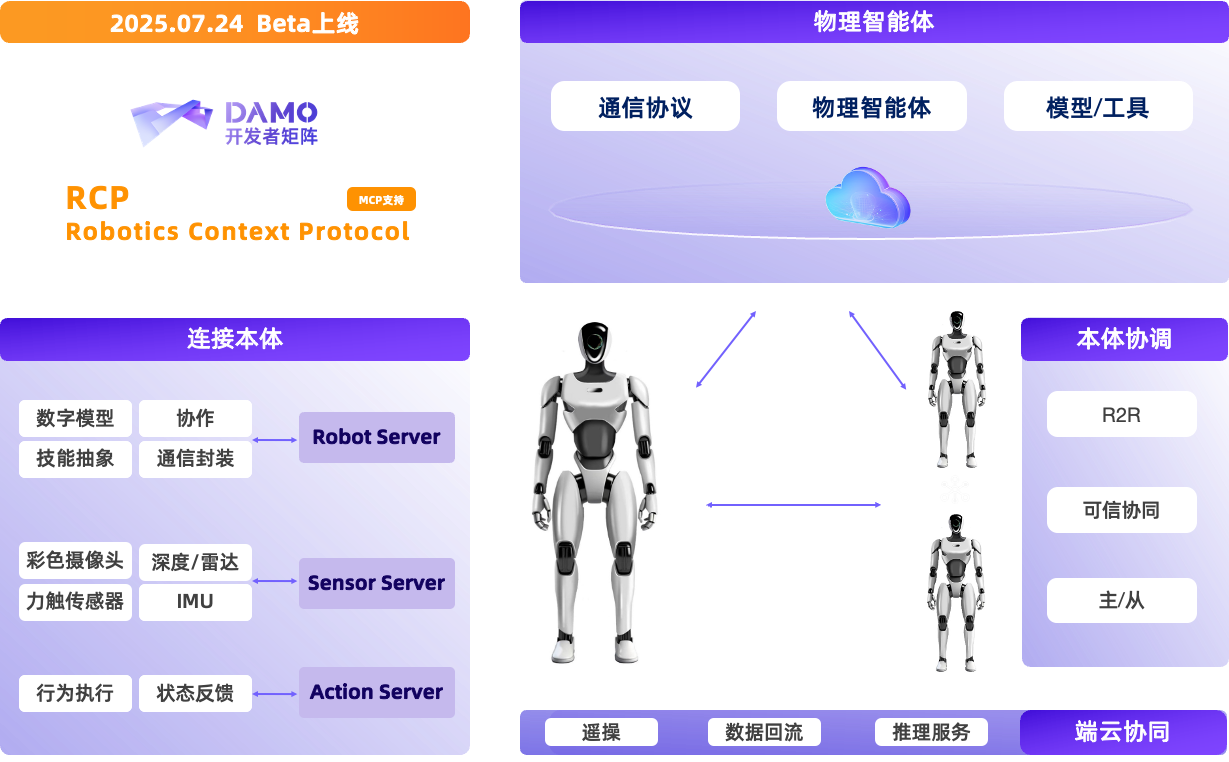
具體而言,RynnRCP包括RCP框架和RobotMotion兩個主要模塊。RCP框架旨在建立機器人本體與傳感器的連接,提供標準化能力接口,並實現不同的傳輸層和模型服務之間的兼容。RobotMotion則是具身大模型與機器人本體控制之間的橋樑,能將離散的低頻推理命令即時轉換為高頻的連續控制信號,實現平滑、符合物理約束的機器人運動。同時,RobotMotion還提供了一體化仿真-真機控制工具,幫助開發者快速上手,支持任務規控、仿真同步、數據採集與回放、軌跡可視化等功能,降低策略遷移難度。
大會上,達摩院還宣佈開源兩款具身智能大模型。RynnVLA-001是達摩院自主研發的基於視頻生成和人體軌跡預訓練的視覺-語言-動作模型,其特點是能夠從第一人稱視角的視頻中學習人類的操作技能,隱式遷移到機器人手臂的操控上,從而讓機械臂操控更加連貫、平滑,更接近於人類動作。
世界理解模型RynnEC將多模態大語言模型引入具身世界,賦予了大模型理解物理世界的能力。該模型能夠從位置、功能、數量等11個維度全面解析場景中的物體,並在複雜的室內環境中精準定位和分割目標物體。無需3D模型,該模型僅靠視頻序列就能建立連續的空間感知,還支持靈活交互。
據瞭解,達摩院正積極投入具身智能,聚焦於系統和模型研發,與多方共建產業基礎設施,包括硬件本體和標準組件適配、數據採集,以及技術社區DAMO開發者矩陣等,希望拓展機器人的產業空間,加速場景落地。達摩院還在上月開源了WorldVLA模型,首次將世界模型與動作模型融合,提升了圖像與動作的理解與生成能力,受到業界關注。