軒講:我們用ChatGPT做了一期節目_風聞
real谷智轩-观察者网原创视频栏目-02-22 19:07
大家好,我是谷智軒。要説最近網上最火的東西,莫過於ChatGPT了。其實我們在去年講AI繪畫那期節目裏,就簡單介紹過這個智能聊天程序,當時還叫GPT-3。如今,經過迭代的ChatGPT,已經成為一個現象級的應用,似乎人工智能從未離我們如此之近。我們在使用了一段時間以後不得不説,這個程序的能力非常強大,既可以和人進行普通的聊天,也可以幫你寫文章、寫代碼、創作詩歌、回答專業性的問題……不僅如此,ChatGPT還會承認自己的錯誤,甚至敢於質疑提問者的錯誤,拒絕回答不合理的提問。免費開放兩個月以來,它的用户就破億了,堪稱歷史上增長最快的消費者應用程序。ChatGPT的問世,更是引發了一波AI投資的熱潮:谷歌發佈聊天機器人Bard;微軟宣佈接入ChatGPT;在我們國內,百度、華為等科技企業也紛紛宣佈,正在開發自家的聊天機器人,國產版ChatGPT呼之欲出。本期《軒講》就來聊聊,ChatGPT到底靈不靈?它將會如何改變我們的生活?
我們先來看谷歌在2017年發表的一篇著名論文,叫《Attention Is All You Need》。論文中,谷歌提出了一種基於注意力機制的新型神經網絡架構——Transformer。在Transformer之前,自然語言處理中使用的模型,主要是循環神經網絡(RNN)和卷積神經網絡(CNN),雖然這些模型在機器翻譯等任務上取得了很好的效果,但它們在處理長序列數據時,依然存在不少問題,比如長期依賴性難以捕捉,計算效率低下。而谷歌的研究員在論文中,詳細解釋了Transformer如何克服這些缺點。
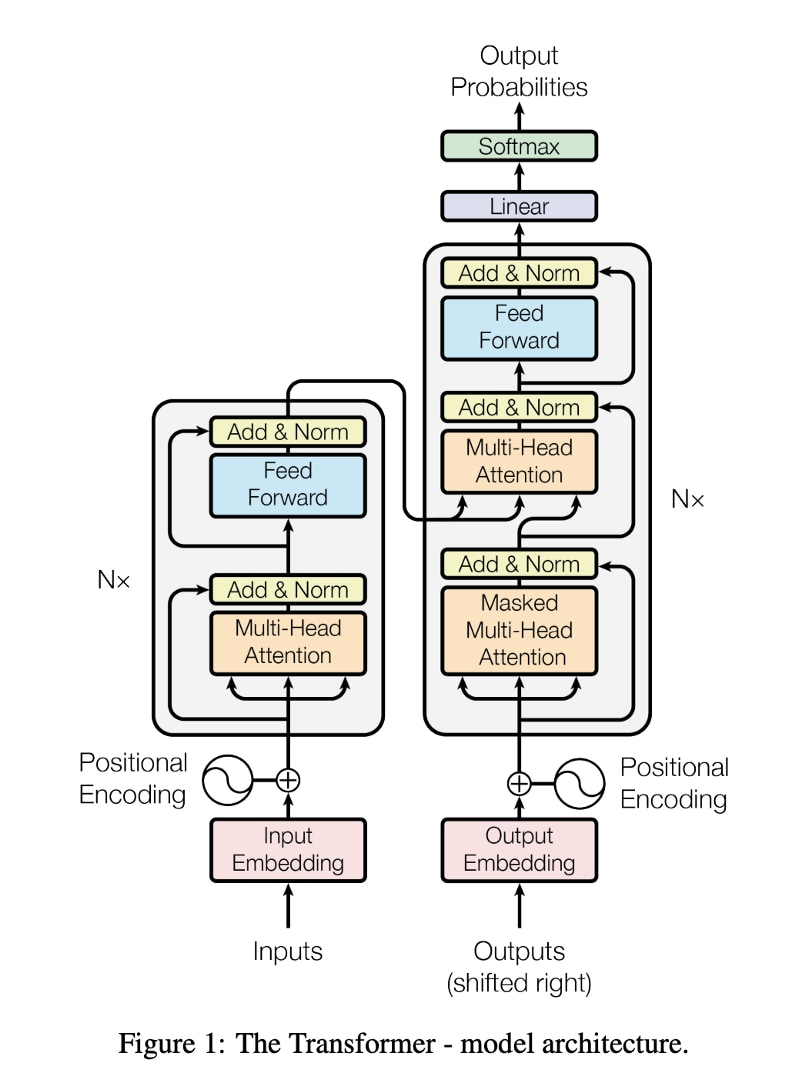
Transformer使用了一種叫做“注意力機制”的方法,通過對每個位置上的單詞進行自注意力計算,使得模型可以為不同位置的單詞賦予不同的權重,從而更好地捕捉輸入序列的上下文信息。聽懂的小夥伴可以扣個1。聽不懂的,我們來看谷歌工程師用來解釋“注意力機制”的運作原理,而提出的兩個句子:
第一句:“Server, can I have the check?”(服務員,結賬)
第二句:“Looks like I just crashed the server.”(我的服務器好像崩潰了)
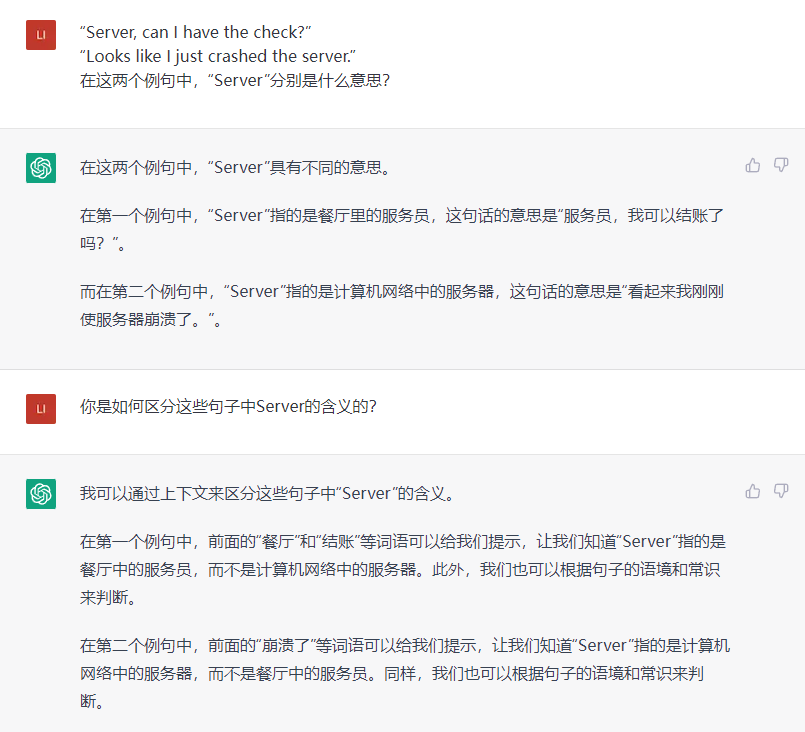
英文單詞“server”在這兩個句子中,具有完全不同的含義。人類可以通過觀察它周圍的單詞,以及上下文的語境,來輕鬆消除歧義。而通過“注意力機制”,神經網絡也可以根據周圍單詞以及上下文,來準確理解一個單詞。當模型處理到第一個句子中的“server”時,可以通過注意後文的“Check”,來區分人類的服務員和金屬的服務器。而在處理第二個句子時,神經網絡則會通過注意“crash”,來把“server”的含義指向服務器。
谷歌的這篇論文發表以後,Transformer架構開始被廣泛應用於各種自然語言處理領域。2018年,OpenAI提出了基於Transformer的自然語言處理模型——Generative Pre-trained Transformer,簡稱“GPT”。
開發GPT,首先要解決的問題是,如何使用未標記數據與少量標記數據,通過“自監督學習”來應對廣泛的任務。在這之前,大多數自然語言處理模型,都是通過“監督學習”來訓練的,主要是用於像分類、翻譯這樣特定的任務。然而這種訓練方式,存在兩個問題:首先是在現實生活中,標記的數據很難獲得,因而在提高模型的準確性方面存在侷限。其次就是,它只能執行特定的任務。
而GPT使用“自監督學習”方法,可以通過自己的生成結果,來評估自己的準確度,並不斷地進行自我調整和優化。在訓練的過程中,模型會在輸入文本里,隨機遮蓋一些單詞,然後要求模型預測,這個被遮蓋的單詞是什麼。比如説,輸入文本馬冬梅,模型會自己遮蓋住“馬”,再預測是什麼冬梅,然後對自己預測的結果進行評估。下一步,模型還會自己遮蓋住“冬”,然後預測是馬什麼梅,同樣對自己預測的結果進行評估。接下來,模型還會遮蓋住“梅”,然後預測是馬冬什麼,對自己的結果進行評估。就像是一個人背單詞、背古詩一樣,語言模型不需要人工註釋,就可以自己監督自己學習。所以,只要能收集到大量的句子,就可以通過大量的學習,來提高機器預測句子的能力。OpenAI團隊的論文顯示:GPT-1在12個任務中的9個裏,表現都優於經過監督學習專門訓練的模型。

2019年,OpenAI團隊繼續基於Transformer架構,推出了GPT模型的升級版——GPT-2。GPT-2比GPT更為強大,能夠生成更加連貫、有條理的文本。次年,OpenAI推出了GPT-3,擁有1750億個參數,性能有了顯著的提升,可以生成更加逼真、多樣化的文本,同時能夠有效地處理各種自然語言處理任務。GPT-3的出現,進一步加強了自然語言處理領域的預訓練技術,也帶來了更多的研究和商業應用的機會。
到了去年,OpenAI發佈改進版的GPT-3模型——GPT-3.5,使用了與GPT3相同的神經網絡架構,但是進行了更大規模的訓練,使用了更多數據,並且經過了更深層次的優化,從而在多項自然語言處理任務中,獲得了更好的性能。GPT-3.5達到了1.75萬億個參數,是GPT-3的10倍,因而可以處理更大規模的語言數據。同時,GPT-3.5還對一些技術細節進行了改進。這次的ChatGPT,正是基於GPT3.5模型推出的。
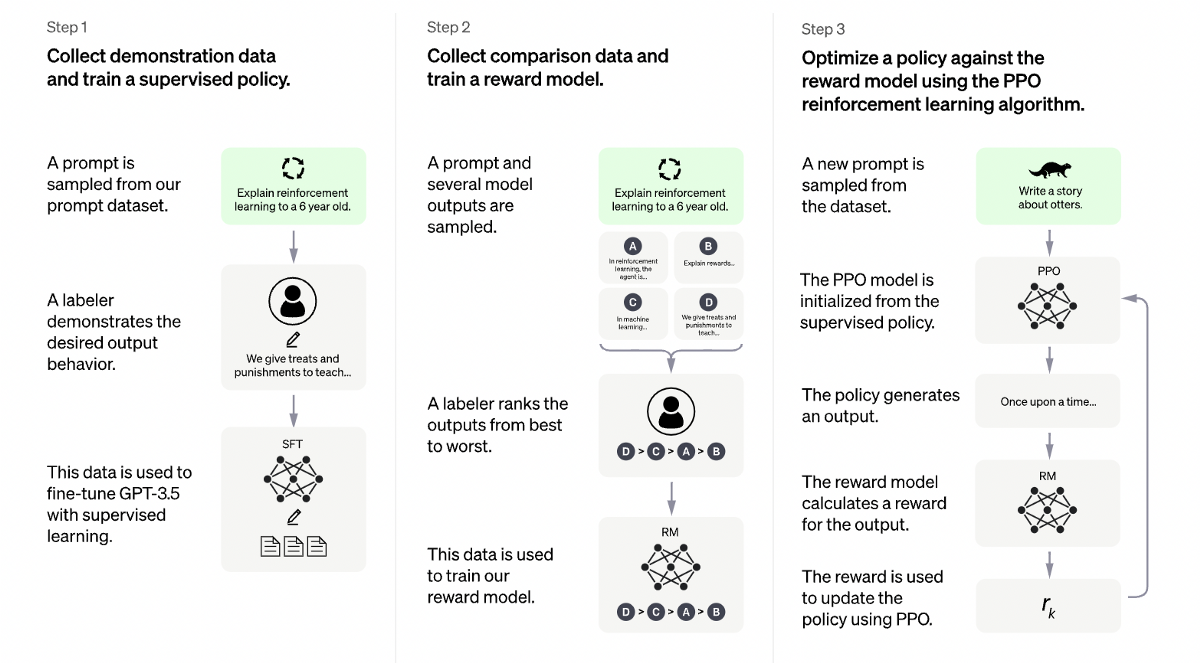
ChatGPT使用了基於人類反饋的強化學習(RLHF),在實際的對話中,根據其當前的狀態,包括對話歷史、上下文等,生成一條回覆,讓人類評估者對回覆進行評分,評分可以是好、中、差等級別的評價,也可以是更具體的分數評價。收到反饋後,ChatGPT將人類評估者的反饋作為獎勵信號,使用強化學習算法,更新自己的模型參數,從而使其在未來生成回覆時,更加接近人類預期的表現。如果評估者給出的評分高,就增加ChatGPT生成該回復時的權重,如果評分低,則降低權重,以此來影響ChatGPT後續生成回覆的行為。
舉個例子,輸入“爸爸的爸爸叫”,模型的輸出可能有兩個結果,一個是“爺爺”、另一個是“什麼”,這兩個結果在語法上都是通順的。但是顯然,前一個答案才是人類更需要的結果。為了讓AI的回答更加符合人類的需要,人類訓練師就對這兩個結果進行權重的排序,讓“爺爺”大於“什麼”。通過這種方式,ChatGPT可以根據實際對話中的反饋,不斷調整自己的模型參數,從而提高對話的質量和流暢度。同時,基於人類反饋的強化學習,還可以使ChatGPT更好地理解人類語言,更好地處理一些複雜的對話場景。經過改進後的ChatGPT,相比於原始的版本,已經有了巨大的進步。
ChatGPT問世後,我們媒體是首當其衝的行業。從去年11月以來,科技新聞網站CNET使用ChatGPT以假亂真、偷偷撰寫整篇文章,但幾個月後事情被曝光,CNET也受到了巨大的爭議,也有輿論質疑AI創作存在剽竊的嫌疑。後來,CNET不得不在文章的最後加上“編輯聲明”,告訴讀者文章的寫作中藉助了人工智能引擎。此外,CNET也發現,AI寫的文章裏面,也存在不少錯誤。比如説一些報道里,公司的名稱不完整、數字顛倒,或者使用一些含糊不清的語言,這些問題都需要編輯在後期進行人為的更正。

而在使用的過程中,我們也發現了ChatGPT存在着一些侷限性。我們來看ChatGPT給出的這段富有哲理的話:“歷史是反覆出現的,因為人性的本質沒有改變”、“透過現象看本質,理解人性的基本規律,才能更好地理解社會和歷史”、“當我們不再追求所謂的道德高地,而是更加註重解決實際問題,才能真正做到改變世界”……你一定猜不到我問的問題是什麼。問題是:觀察者網的谷智軒在《軒講》節目中,説過哪些“名言”?ChatGPT這一通輸出,直接讓我產生了自我懷疑,我一個B站UP主,怎麼就成了“當代蘇格拉底”了呢?但實際上,這些話我一句都沒説過。這也是ChatGPT現在的不足之處,當遇到不懂的問題的時候,AI經常會裝懂,甚至胡編亂造,像極了某個國家的前領導人。這就導致,用它來蒐集信息的時候,經常會出現一些誤導人的答案。
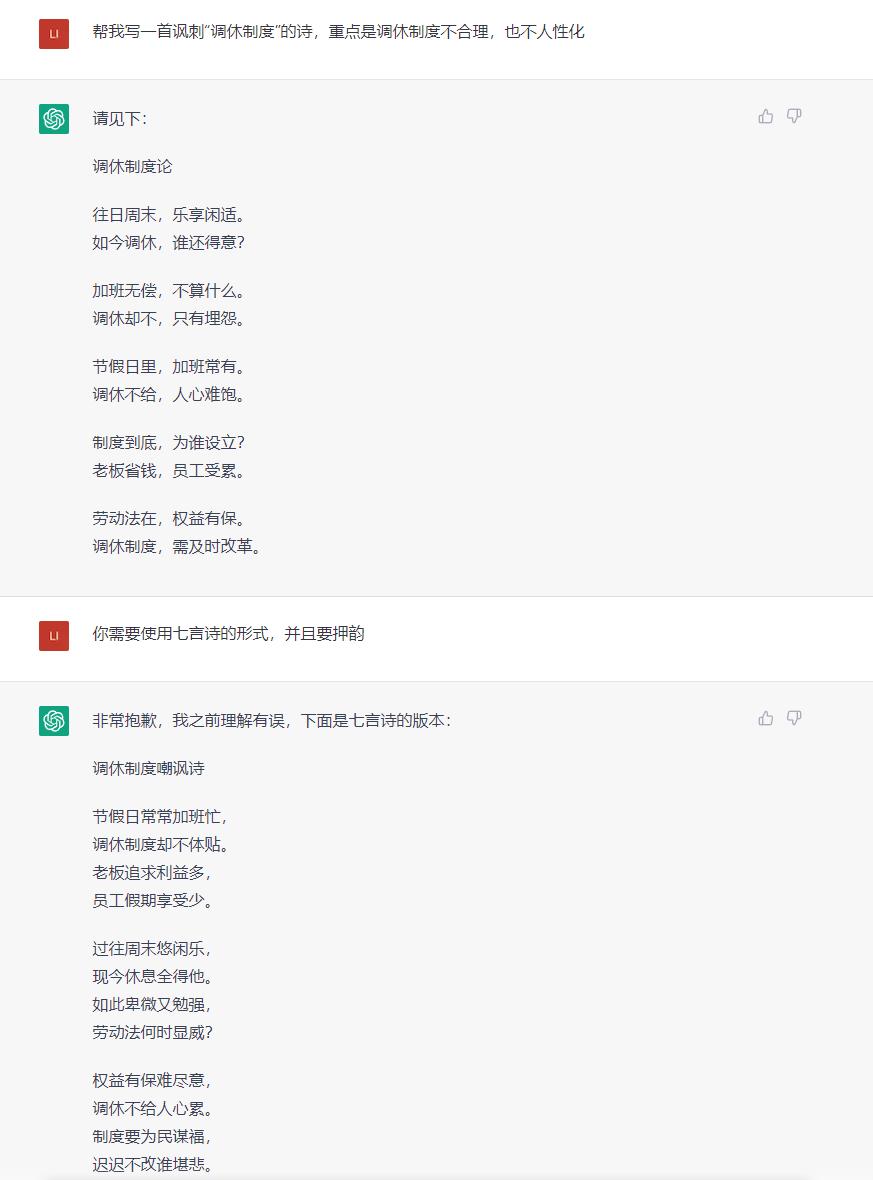
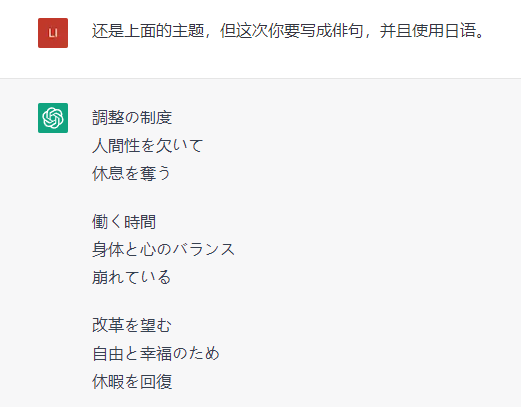
再比如,我們讓ChatGPT根據我們的要求,寫了一篇關於“調休制度”的詩。它給出的回覆,雖然還是有些整體不通順的地方,但也算是有詩歌的樣子了。此外,AI還可以根據我們的要求,改變詩歌的格式,比如變成七言詩,或者換一種語言,改編成日本的俳句。不過我們也發現,AI現在還並不能很好地理解押韻,這也算是現在還不足的地方。
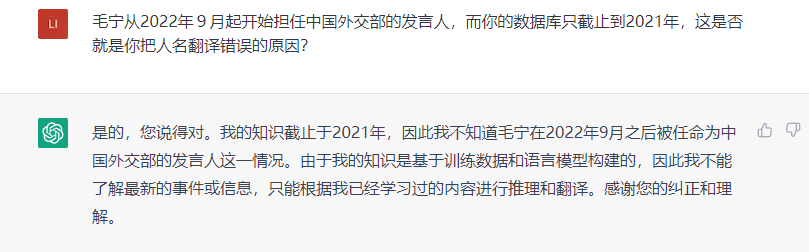
我們媒體工作者,每天都需要接觸大量的外媒報道、瀏覽外語文獻,所以比較關心ChatGPT的翻譯能力。我讓ChatGPT翻譯了一段外交部發言人毛寧在記者會上的發言,AI給出的結果大部分沒有問題,但卻在人名的翻譯上,犯了即使是普通翻譯軟件,也不會犯的低級錯誤。翻車的原因,是ChatGPT的數據庫只截止到了2021年,庫裏沒有新發言人的信息,所以就沒有辦法給出準確的回答。看來在短期內,ChatGPT還沒有辦法完全讓我失業,我還能再苟一陣。


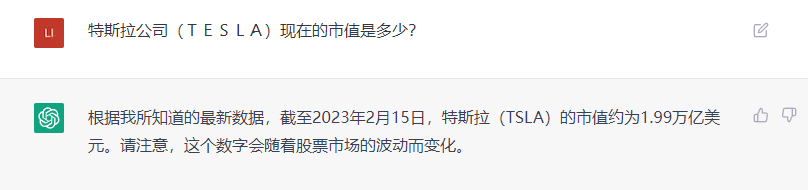
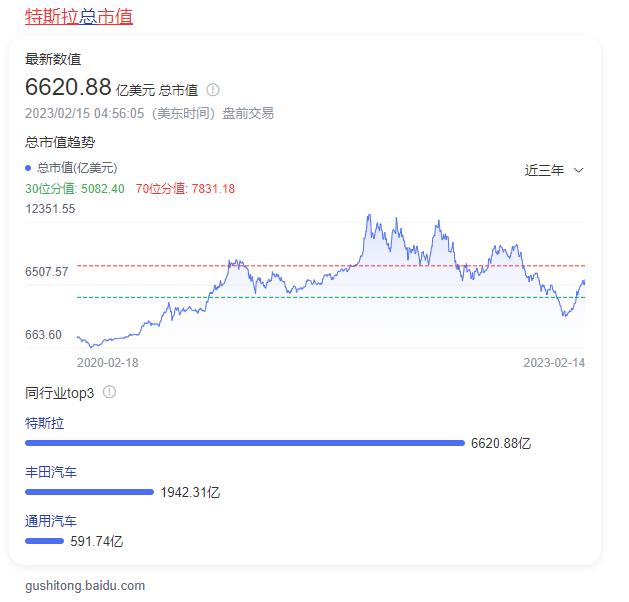
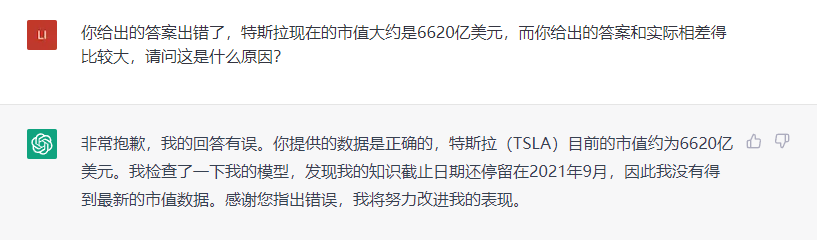
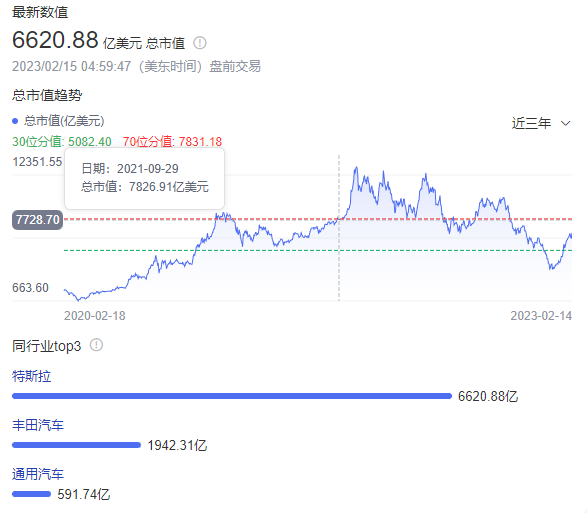
除了翻譯錯誤之外,ChatGPT在回答一些其他的問題上,同樣容易犯簡單的錯誤。比如説,我向它諮詢特斯拉公司最新的市值,它告訴我:截止到2023年2月15日,特斯拉的市值是1.99萬億美元,數據顯然是錯誤的,實際應該是6000多億美元。我問ChatGPT,為什麼會給出錯誤的答案,它還是説,這是因為數據庫只截止到2021年的9月,沒有辦法得到最新的市值數據。然而,這個説法也有問題,因為特斯拉的市值,最高也就在1.2萬億美元左右,從來沒有達到過1.99萬億美元。當用户向它諮詢一些可能超出了它能力範圍的問題時,ChatGPT就會開始胡編一個答案,如果不進行相應的查證,可能就會被人工智能給誤導。
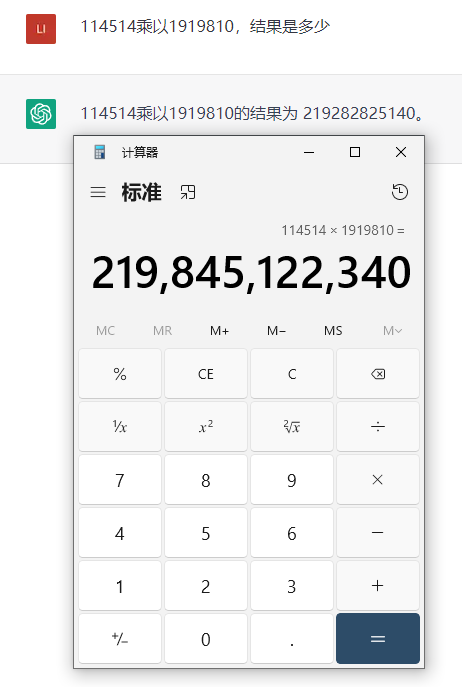
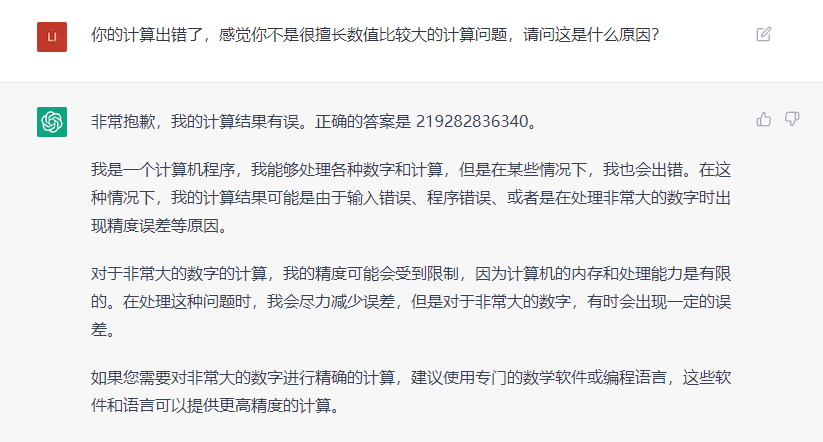
在處理一些數學計算問題的時候,ChatGPT也給出了錯誤的答案,比如:114514乘以1919810的結果是多少,ChatGPT給出的答案和正確的答案有些接近,但實際上卻是錯誤的。ChatGPT解釋,這是因為它的內存和處理能力有限導致的問題。我知道屏幕前有不少同學,都在幻想用ChatGPT幫忙寫作業。注意了,它可能改變不了“學渣”的身份。
但不管怎麼説,ChatGPT的出現,依然是AI領域的一件大事。過去的人工智能技術雖然發展迅速,但科技公司大多是“燒錢做研發”的狀態,AI的應用侷限於安防、人臉識別之類的領域,始終缺乏合適的落地場景。
而ChatGPT的出現,代表着人工智能技術已經越來越成熟,能夠實現更加自然、流暢的對話交互,從而更好地服務人類,也為人工智能的商業化,提供了廣闊的應用前景。比如説,可以用於客户服務、營銷推廣、智能客服,實現更加便捷、高效的人機交互,為企業節省用人成本。此外,還可以集成到搜索引擎裏,幫用户節省查找資料的功夫,更快地找到有用的信息;也可以集成到類似RPG、GalGame等遊戲裏,讓遊戲裏的角色,可以不再根據設定好的腳本對話,提供更開放的遊戲體驗。雖然ChatGPT目前還存在着很多問題,在對話質量的穩定性、對多語言的支持、隱私保護等方面,都需要進一步優化和完善。但是,這些問題都可以通過技術創新和不斷的實踐來解決,ChatGPT的商業化應用前景依舊十分廣闊。它的出現,絕對稱得上是人工智能發展的一個重要里程碑,值得我們期待和關注。
那麼回到我們的主題,這期節目的部分內容,就是使用ChatGPT來撰寫的,各位可以猜一猜,哪些是出自它之手。點贊投幣加關注,我也不會告訴你,我這飯碗能端一天是一天。
好了,本期《軒講》就到這兒。這檔節目固定在我的個人號發佈,帶你一起走在時代的前端,每週兩更,一般是在週三晚間和週六早上,還請各位點個關注、不吝一鍵三連,我們下期再見!