OpenAI發佈災備架構應對大模型風險,AI安全問題正在成為關注焦點
唐晓甫
(觀察者網訊)當地時間12月18日,OpenAI在官網發佈災備架構測試版介紹文檔,描述該架構應對流程以跟蹤、評估、預測和防範日益強大的模型帶來的災難性風險。OpenAI規定了四個安全風險等級,並表示只有得分在“中”或以下的模型才能部署。

OpenAI災備架構測試版文檔 圖片來源:OpenAI
據路透社報道,由微軟支持的OpenAI只會在確認沒有網絡和核等方面安全威脅的情況下才會部署其最新的技術。此外,該公司還正在創建一個諮詢小組來審查AI安全報告,並將其審查結果發送給公司的高管和董事會。這樣可以確保雖然AI運行的決策權在高管手中,但董事會可以推翻這些決策。
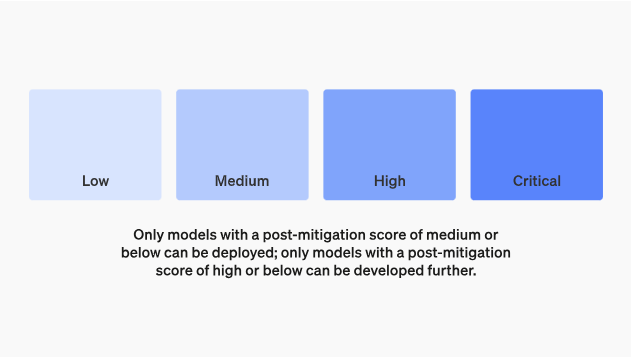
OpenAI災備架構 圖片來源:OpenAI
該文檔的提出被認為是OpenAI進一步加強AI應用安全監管的一個嘗試。近期由於AI的快速發展,AI應用的安全性問題被廣泛關注。
對於AI應用安全這一問題,長期以來有兩派觀點,即有效加速主義和AI對齊思想。
有效加速主義(Effective accelerationism,簡稱為“e/acc”)是一種21世紀基於科技發展而興起的哲學思想。其支持者一般認為,由人工智能驅動的進步是一種偉大的社會平等器,應該被推動前進。因此,不惜一切代價,採用包括加速商業化在內的一切手段,推動技術進步才是唯一在道德上合理的行動方針。值得注意的是,一般認為OpenAI的現任CEO山姆·奧特曼(Sam Altman)是有效加速主義的支持者。
與有效加速主義對應的是AI對齊(AI alignment)思想,該派理論則更注重AI安全問題,強調人工智能系統的對齊問題,即如何確保未來超出人類智能的超級人工智能系統的行動目標與人類的目標一致。因為如果人工智能系統的目標與人類的目標不一致,可能會導致不可預見和潛在的危險後果。OpenAI中負責AI安全並參與罷黜CEO山姆·奧特曼的首席科學家伊利亞·蘇茨克韋爾(Ilya Sutskever)等人,以及此前從OpenAI脱離並創立大語言模型Claude的達里奧·阿莫代(Dario Amodei)等人都是AI對齊思想的支持者。
據路透社、The Information等媒體報道,之前震驚世界的OpenAI“宮鬥”事件就源自於有效加速主義和AI對齊思想的路線之爭。
11月22日,路透社報道稱OpenAI擁有一個尚未公佈的新模型Q*。該模型能夠解決某些數學問題,雖然現階段其數學成績僅達到小學生的水平,但在相關測試中取得的成績讓研究人員對Q*未來的成功非常樂觀,並認為Q*在推理模型方面相較於之前的大模型有了巨大的進步。這可能意味着人類將快速實現完全超越人類本身智能的超級AI。
據悉,Q*的出現加劇了包括首席科學家伊利亞·蘇茨克韋爾在內對於AI安全性的擔憂,並最終促使董事會決定解僱支持有效加速主義的山姆·奧特曼。
值得注意的是,早在今年3月,包括前OpenAI投資者,著名人士馬斯克等上千人曾簽署聯名信,公開信呼籲人類暫停開發比目前GPT-4模型更強大的人工智能,為時至少6個月。
近期除了OpenAI在官網發佈災備架構測試版外,由OpenAI首席科學家伊利亞牽頭的,於今年7月建立地“超級對齊”團隊,在本月15日發佈了其成立以來的第一篇論文。在其最新的研究中,該團隊提出了一個技術路線:使用GPT-2級別的AI對GPT-4進行監督並伴以一定的置信度損失,實現了對於GPT-4的微調。這樣的GPT-4可以在NLP任務上恢復到接近GPT-3.5級別AI的性能。
該論文指出,通過上述方法可以實現“弱到強泛化”(Weak-to-Strong Generalization)訓練,證實了我們可以通過使用更弱、更可控的模型來微調更強大的人工智能模型,使其達到與傳統訓練方法所訓練出的AI更相近的性能。這為“AI對齊”的設想提供了一條實際可行的技術路徑。

論文截圖 圖片來源:OpenAI
該論文和災備架構文檔的發表同樣也意味着,OpenAI正在試圖研究如何監管潛在的全面超越人類智能的超級AI。
本文系觀察者網獨家稿件,未經授權,不得轉載。